DXR: Beyond Two Billion IPv4 Routing Lookups per Second in Software
Overview
DXR is an IPv4 routing lookup scheme based on transforming large routing tables to compact lookup structures which easily fit into cache hierarchies of modern CPUs. It supports various memory/speed tradeoffs, and its throughput scales almost linearly with the number of CPU cores.The most compact configuration, D16R, distills a real-world BGP snapshot with 513,644 IPv4 prefixes and 239 distinct next hops into a structure consuming only 932 Kbytes, less than 2 bytes per prefix, and exceeds 100 million lookups per second (MLps) on a single commodity CPU core in synthetic tests with uniformly random queries. Some other DXR configurations exceed 200 MLps per CPU core at the cost of increased memory footprint, and deliver aggregate throughputs exceeding two billion lookups per second with multiple parallel worker threads.
How does this work?
DXR partitions the entire IPv4 address space into 2^K uniform blocks called chunks. K most significant bits of each search key are used to directly index the primary or direct lookup table. If the corresponding chunk does not contain any IPv4 prefixes more specific than K, the search completes as the index into the next hop table is encoded in the direct table entry. If the chunk contains IPv4 prefixes more specific than K, those are encoded as a sorted array of address ranges, which can be fairly efficiently searched in logarithmic time, again yielding an index in the next hop table.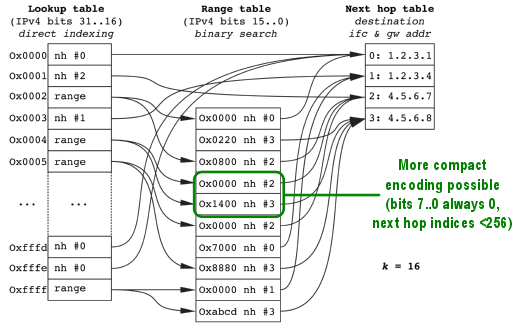
Because the majority of IPv4 prefixes announced in global routing tables are (still) /24 or less specific, a further optimization is possible for chunks containing only such prefixes and only pointing to next hop table entries which can be encoded using 8 bits. In such cases the 8 least significant bits of each range base are guaranteed to be all zeros, which permits range entries to be encoded using only two bytes, thus improving cache hit rates.
Additional details on data structures, incremental updating algorithms and performance analysis can be found in our CCR paper.
Note that there were other proposals predating DXR which explored range-based LPM, such as Lampson-Varghese multiway lookups. The novelty of DXR is in compact encoding of range lookup structures combined with a trivial search procedure.
Code
DXR is based on RangeIPLookup, an experimental IPv4 routing lookup element distributed with the Click modular router since 2005. We refined and ported it to the FreeBSD kernel where DXR was coupled to the historic BSD radix tree as its auxiliary database, which simplified adding support for fast incremental updating of lookup structures.DXRIPLookup is now available as a Click element, along with a few other related modules: BSDIPLookup, which can be used as a standalone lookup module but also serves as DXR's auxiliary database; DirectIPLookup, a (re)implementation of the DIR-24-8 lookup scheme which unlike the original version now also supports fast incremental updating; and finally BSDIP6Lookup, a Click-IP6 wrapper around the traditional BSD radix tree code.
Click modules are available here: dxr_click_20140423.tgz
To install the modules, unpack the above archive in click's top-level directory. You'll have to delete the existing elements/ip/rangeiplookup.* files since that module depends on an older version of DirectIPLookup element, and is made obsolete by the new DXRIPLookup implementation. Then configure, build and install Click using the standard procedure.
By default DXRIPLookup is configured to resolve 20 most significant bits of lookup keys via direct table lookups (D20R). To experiment with different DXR configurations, edit file dxriplookup.hh around line 100 and set the macro DXR_DIRECT_BITS to the desired value, and then rebuild Click. The choice of DXR_DIRECT_BITS (or K) determines the balance between the overall memory footprint of the lookup structures and the number of binary search iterations required to find the next hop using range tables, as outlined in the graph below:
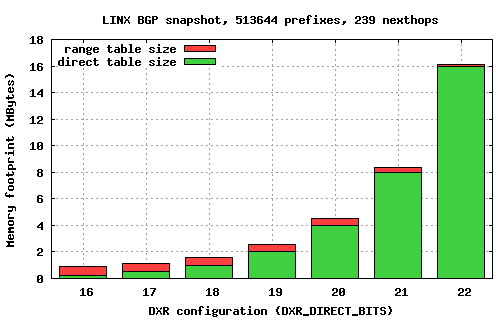
| 1 | 2 | 3-4 | 5-8 | 9-16 | 17-32 | 33-64 | 65-128 | 129-256 | |
| 16 | .75318 | .02029 | .04551 | .04385 | .04750 | .04628 | .03082 | .01167 | .00087 |
| 17 | .80845 | .01961 | .04394 | .04278 | .03985 | .02984 | .01428 | .00121 | .00003 |
| 18 | .85712 | .02175 | .04058 | .03472 | .02792 | .01578 | .00209 | .00003 | 3.8E-6 |
| 19 | .90347 | .01829 | .03194 | .02596 | .01699 | .00330 | .00005 | 0 | 1.9E-6 |
| 20 | .93821 | .01400 | .02545 | .01732 | .00494 | .00006 | 4.8E-6 | 0 | 9.5E-7 |
| 21 | .96177 | .01289 | .01826 | .00697 | .00008 | 8.5E-6 | 1.9E-6 | 4.7E-7 | 0 |
| 22 | .97907 | .01073 | .01004 | .00013 | .00001 | 2.6E-6 | 1.2E-6 | 2.3E-7 | 0 |
Test vectors
The three test vectors below have been generated from BGP snapshots taken from different routeviews.org routers on April 22, 2014:
linx.click.bz2: 513643 IPv4 prefixes, 239 nexthops
paix.click.bz2: 504818 IPv4 prefixes, 58 nexthops
eqix.click.bz2: 493049 IPv4 prefixes, 58 nexthops
Synthetic benchmarks
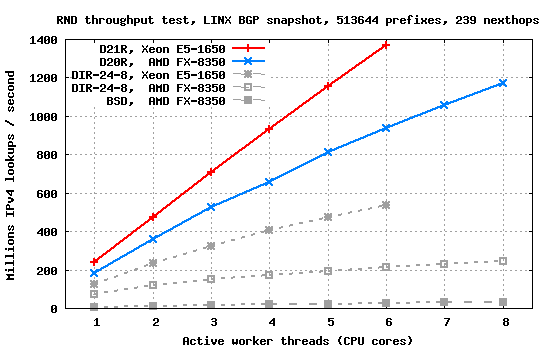
DXRIPLookup and DirectIPLookup elements include handlers for measuring their lookup throughput potential using synthetic streams of random keys. Three different test scenarios are supported.The SEQ (sequential) test introduces artificial dependencies between subsequent queries, which essentially prevent out-of-order execution circuitry on modern CPUs from pipelining cache / memory accesses from multiple search requests. Since Click currently processes packets one-by-one (just as most contemporary operating systems do), this test provides reasonably realistic estimates on how fast the lookup elements would work in real Click configurations.
The RND (random) test indicates how fast lookups could be performed if they would be done in batches, a technique which is becoming increasingly popular (and necessary) in (software) packet processing systems (see Netmap or PacketShader for example). There are no artificial dependencies between lookup requests so they can be transparently pipelined by CPU's OOO circuitry, which significantly improves the throughput compared to the one-by-one packet processing mode.
The REP (repetitive) test operates in the same mode as the RND test, but each key is used eight times within a short timeframe in an attempt to mimic locality in traffic patterns. Since after the first query lookup structures will migrate higher in the CPU cache hierarchy, subsequent requests for the same key will be resolved faster, thus yielding higher throughputs.
The benchmarks below were obtained using the LINX BGP snapshot on four different machines:
E5-1650: Intel Xeon, 12 MB L3 cache, 3.2 GHz
(turbo freq and HT disabled), FreeBSD 9.2
FX-8350: AMD FX, 8 MB L3 cache, 4.0 GHz
(turbo freq disabled), FreeBSD 9.2
i7-4771: Intel Core i7, 8 MB L3 cache, 3.5 to 3.9 GHz
(HT disabled), Debian 3.13.10-1
i5-3210M: Intel Mobile Core i5, 3 MB L3 cache, 2.5 to 3.1 GHz
(HT disabled), FreeBSD 9.2
And here are the results:
| SEQ test, single thread, uniformly random keys, MLps throughput: |
| BSD | DIR-24-8 | D16R | D18R | D20R | D21R | D22R | |
| E5-1650 | 4.7 | 27.5 | 67.1 | 57.0 | 62.1 | 63.1 | 60.6 |
| FX-8350 | 4.7 | 24.8 | 71.7 | 72.7 | 86.6 | 62.1 | 45.3 |
| i7-4771 | 4.9 | 19.9 | 88.5 | 79.3 | 79.3 | 76.5 | 37.8 |
| i5-3210M | 4.1 | 16.1 | 72.0 | 69.2 | 82.4 | 29.7 | 19.1 |
| RND test, single thread, uniformly random keys, MLps throughput: |
| BSD | DIR-24-8 | D16R | D18R | D20R | D21R | D22R | |
| E5-1650 | 4.8 | 135.0 | 93.7 | 134.4 | 211.5 | 248.7 | 247.6 |
| FX-8350 | 4.8 | 75.2 | 102.7 | 144.9 | 190.5 | 171.9 | 122.2 |
| i7-4771 | 4.9 | 137.8 | 123.5 | 179.1 | 273.3 | 308.5 | 141.6 |
| i5-3210M | 4.1 | 92.1 | 95.1 | 140.9 | 230.4 | 118.5 | 99.9 |
| REP test, single thread, uniformly random keys, MLps throughput: |
| BSD | DIR-24-8 | D16R | D18R | D20R | D21R | D22R | |
| E5-1650 | 8.9 | 223.1 | 128.0 | 210.5 | 327.3 | 361.2 | 290.5 |
| FX-8350 | 9.1 | 148.5 | 162.5 | 232.0 | 297.9 | 267.8 | 194.2 |
| i7-4771 | 8.8 | 307.8 | 172.0 | 294.6 | 465.2 | 490.7 | 206.9 |
| i5-3210M | 8.2 | 186.4 | 129.3 | 212.2 | 312.4 | 217.1 | 191.3 |
How to reproduce:
Unpack one of the provided test configurations and start Click with a
control socket listener:
cpx% cd click cpx% ./userlevel/click -p 1234 linx.click |
Then, in another terminal, connect to the control socket and check the status of the lookup element:
cpx% telnet localhost 1234 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. Click::ControlSocket/1.3 read rt.stat 200 Read handler 'rt.stat' OK DATA 428 DXRIPLookup (D20R): 513644 prefixes, 239 unique nexthops Lookup tables: 4194304 bytes direct, 512148 bytes range (9.1 bytes/prefix) Direct table resolves 93.8% of IPv4 address space Longest range chunk contains 176 fragments Physical chunks: 40247 short, 1416 long Physical fragments: 237728 short, 9173 long Aggregated chunks: 63313 short, 1477 long Aggregated fragments: 306484 short, 9354 long Last update duration: 909.6 ms |
The test variant can be selected by writing an integer number to the bench_sel handler, where the SEQ test corresponds to 0, the RND test to 1, and the REP test to 2. The benchmark can be triggered by reading from the bench handler:
write rt.bench_sel 1 200 Write handler 'rt.bench_sel' OK read rt.bench 200 Read handler 'rt.bench' OK DATA 108 DXRIPLookup (D20R), RND test, uniformly random keys: 268435456 lookups in 1.406164355 s (190.9 M lookups/s) |
The new DirectIPLookup element provides the same control handlers for configuring and executing synthetic benchmarks as DXRIPLookup does.
Publications
Denis Salopek, Marko Zec, Miljenko Mikuc. Surgical DDoS Filtering With Fast LPM. IEEE Access, Vol. 10, 2022.Marko Zec, Miljenko Mikuc. Pushing the Envelope: Beyond Two Billion IP Routing Lookups per Second on Commodity CPUs. 25th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, 2017. Best Paper Award!
Marko Zec, Luigi Rizzo, Miljenko Mikuc. DXR: Towards a Billion Routing Lookups per Second in Software. ACM Computer Communication Review, Vol. 42(5), 2012, pp. 29-36.
People
zec (at) fer.hrrizzo (at) iet.unipi.it
miljenko (at) nxlab.fer.hr